开云体育(kaiyun)官方网站 ICML 2026|首个视觉话语模子并行想考框架, 一文潜入内在机制


刻下,测试时彭胀范式广大勤奋于增多推理长度。相关词,已有盘问标明,跟着推理长度的抓续增长,以垂直彭胀为中枢的策画范式容易堕入探索僵化等问题。因此,从另一维度拓展推理的宽度显得尤为焦躁。K2.5、Step3-VL 和 LongCat-Flash-Thinking 等模子已在推理宽度方面开展了成心的探索。
但另一方面,在视觉任务中,深度推理仍面对严峻挑战:跟着推理序列的拉长,模子对视觉特征的预防力被不休稀释,导致 “预防力漂移”,进而激勉严重的视觉幻觉。
为此,咱们提倡了 Visual Para-Thinker:这一针对大范围视觉话语模子的首个并行想考框架,并分析了该并行想考框架在视觉任务中进展作用的内在机制。咱们将 Pa-Attention(并行预防力机制)和 LPRoPE (分段学习位置编码)机制融入到咱们的步履中,从而完了了不同推理旅途阻隔性、无偏性和可区分性。

论文标题:Visual Para-Thinker: Divide-and-Conquer Reasoning for Visual Comprehension
论文贯穿: https://arxiv.org/abs/2602.13310
主页贯穿: https://github.com/xuhaoran1/Visual-Para-Thinker
并行推理旅途:以视觉为中心分辨
过往盘问提倡的并行想考范式,其中枢在于通过拓展推理宽度以耕作模子性能,基本原则是 “保抓推理旅途的千般性”。咱们的 Visual Para-Thinker 雷同解任这一原则。相关词,针对视觉话语模子的特质,咱们进一步提倡了一种以视觉为中心的旅途分辨形势,并以为其本色在于对视觉 token 预防力的从头分派。由此提倡了两种视觉分辨的分派风光:块分辨和扫描分辨。
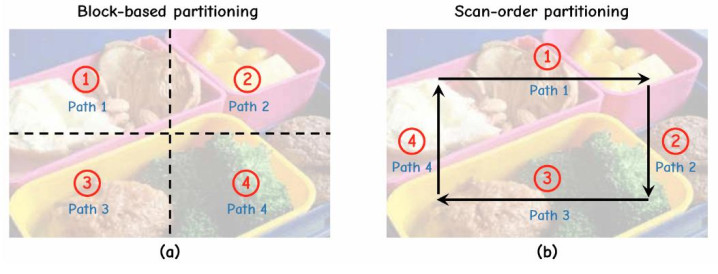
块分辨:这种计策是字据特定的区域子图来分辨推理旅途的。在这个树立方面,每条旅途皆会劝诱特有的视觉预防力漫步,这种漫步集结在指定的子区域,举例左上角、右上角、左下角或右下角等象限,如图 (a) 所示。
扫描分辨:这种步履通过取舍不同的视觉扫描轨迹来区分推理旅途。具体而言,每条旅途代表一种特有的视觉预防力分派,这种分派对应于一个预界说的扫描律例,举例从左到右、从上到下、从右到左以及自下而上,如图 (b) 所示。
这两种视觉分辨形势各有优劣:块分辨天然大略生成不同的子区域,但可能导致不同旅途之间的策画冗余;而扫描分辨虽结构神圣,却容易收缩旅途之间的千般性。为此,咱们取舍羼杂考验计策,将两种分辨形势生成的数据共同用于模子考验,以完了上风互补。
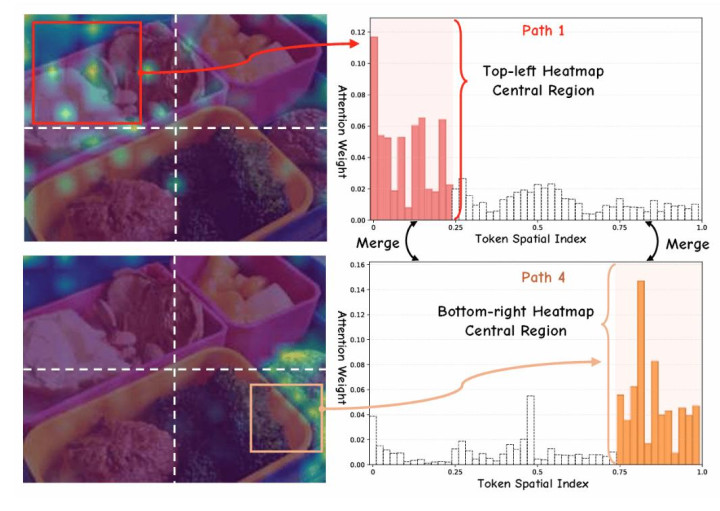
块分辨形势下不同旅途的对视觉令牌预防力分派风光可视化
视觉并行想考框架
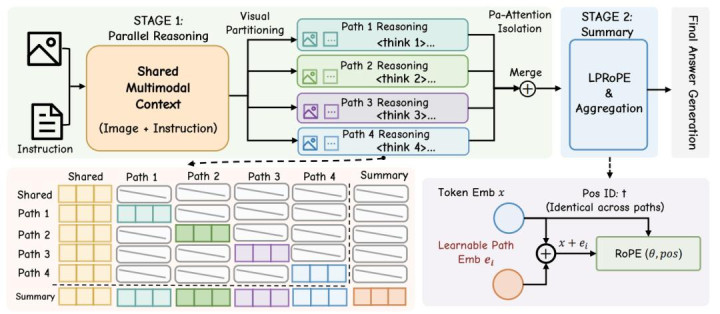
基于以上两种视觉旅途的分辨形势,咱们提倡了视觉并行想考框架。该框架分为并行想考阶段和回来阶段,米兰体育app2026世界杯(中国)官方下载并搬动了不同并行推理旅途的阻隔性、无偏性和可区分性。
并行想考阶段:基于共同的崎岖文,通过视觉分辨这一理念,分派不同推理旅途的想考标的
回来阶段:将不同并行推理旅途的布景信息进行整合,并抽象考虑这些信息以得出最终论断。
阻隔性
为了保证推理旅途的阻隔性,咱们提倡了 Path-aware Attention (旅途感知预防力),不同于因果预防力,旅途感知预防力通过不同think i的极端 token 完了不同旅途的崎岖文阻隔范式。
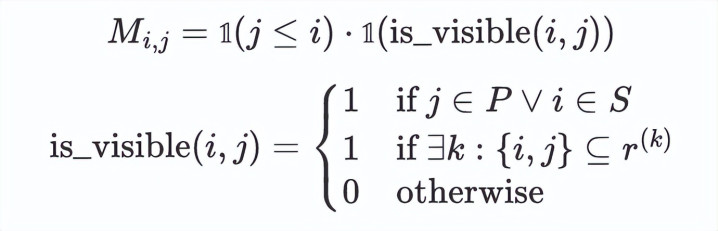
无偏性
为了保证推理旅途的可区分性,过往的作念法将不同旅途的 position id 赋予不同的区间完了旅途的之间的可区分性。相关词,由于谣言语模子的固有偏差,此时不同区间的 position id 存在先后律例,会出现 loss in the middle 等局势,不同旅途的想考权重会存在天生的位置偏差,咱们以为这种步履因为不成将不同推理旅途等同看待,本色上如故是串行想考。基于以上见解,咱们将不同旅途的 position id 赋予调换的区间,开云体育(kaiyun)官方网站具体来说,在并行推理阶段,不同旅途的肇始 token 的 position id 调换
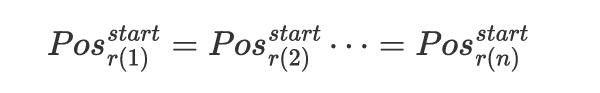
而在回来阶段,回来 token 的肇始 token 则取最长的推理旅途的摈弃 token 的 position id + 1
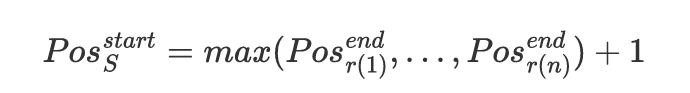
这使得不同推理旅途在 Visual Para-Thinker 模子看来不存在固有的位置偏差,因而保证了无偏性。
可区分性
相关词,上述将不同旅途的位置编码映射为吞并区间的作念法只是保证了其无偏性,但毁伤了不同旅途的可区分性。要是平直使用这种位置编码,会导致 Visual Para-Thinker 浑浊不同的推理旅途,导致终末的后果无理。因而咱们提倡了 Learnable Parallel Rotary Position Embedding (LPRoPE),具体来说,咱们在不同 token 进行旋转位置编码之前,加入该 token 属于的推理旅途的可学习位置编码,将旋转位置编码和可学习的全皆位置编码相集合,最终完了旅途的可区分性。
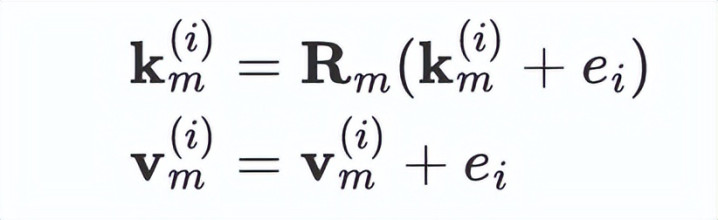
数据与践诺
考验配方
咱们构建了一个包含 163,000 个问题 - 谜底对的并行推理数据集,数据起首包括 LVIS、LAION、Microsoft COCO、PixMoCount、RefCOCO、RefCOCO+ 和 RefCOCOg 等。
在咱们的数据构建框架中,Qwen3-VL-235B-A22BInstruct 充任训练模子。咱们通过在温度为 0.1 的条目下扩充一种交融了基于块的分区和扫描律例分区的羼杂视觉分区计策,为每个样本生成四条以视觉为中心的推理旅途。此外,咱们还愚弄高温的 Qwen3-VL-30B-A3B-Instruct 和 InternVL3 5-241B-A28B 来生成更千般化的数据和检查样本。
江南体育(JNsports)官网app下载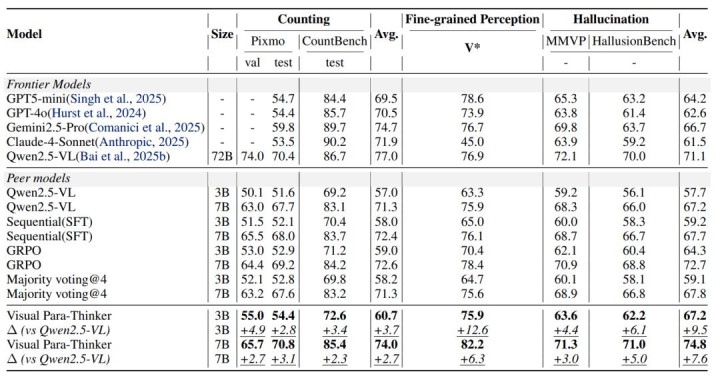
图一
践诺后果
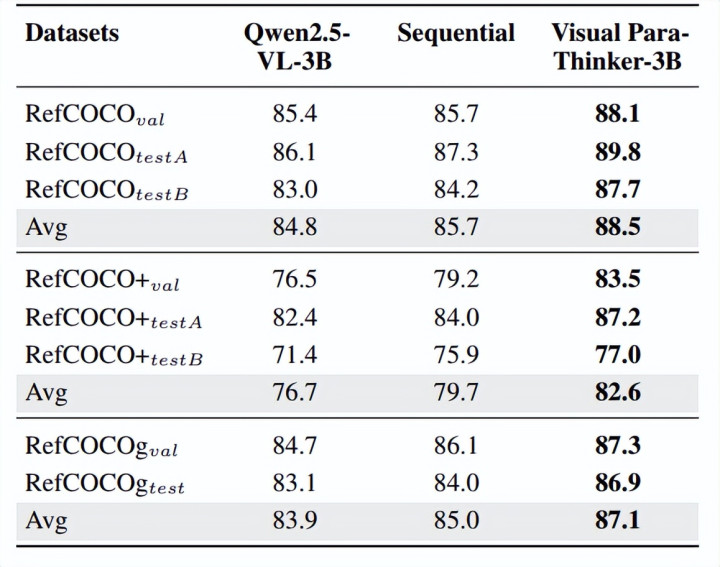
咱们的践诺主要在在以视觉为中心的视觉感知类任务中进行,包括计数任务 (Pixmo,CountBench)、视觉搜索 (V*)、幻觉任务 (MMVP、HallusionBench) 及视觉定位 (RefCOCO) 等多种视觉感知任务,通过开展大批践诺考据了所提步履的灵验性。如图一所示,咱们的步履在 V * 任务上分别在 3B 和 7B 上得回了 12.6 和 6.3 的耕作,另一方面,在幻觉任务上 HallusionBench 上,咱们的步履在 3B 和 7B 上得回了 6.1 和 5.0 的耕作。这充分考据了多模态并行推理在视觉感知类任务上的耕作。另一方面,在 Grounding 任务中,比较于原始的 Qwen2.5-VL,咱们的步履也得回了一定进度上的耕作,这些践诺从各个方面考据了咱们的步履的灵验性。
图二
此外,咱们还探讨了不同视觉任务对分辨风光的偏好。以计数任务为例,其视觉预防力经常分散于图像各处。若取舍块分辨,各旅途的策画后果可能因区域重复而产生积蓄偏差,进而激勉幻觉。因此,在此类任务中,咱们倾向于使用扫描分辨。
从本色上看,块分辨形势通过将不同图像区域分派给不同旅途,完了了显式的预防力分派;而扫描分辨形势则通过蜕变模子对视觉 token 的预防律例与形势,变成一种隐式的预防力分派机制,最终雷同映射为千般化的推理旅途。前者体现了从全局到局部的联想想路,后者则仍保留全局视角。

块分辨形势可能导致不同推理重复策画
写在终末
Visual Para-Thinker 是将并行想考框架应用于视觉话语范围的投砾引珠之作,之后咱们会将并行想考 RL,多轮想考,Agentic RL 等步履连策应用在 Visual Para-Thinker 中,将 Visual Para-Thinker 完了更快更好的彭胀。跟着 K2.5,Step3-VL 和 LongCat-Flash-Thinking 等基座模子关切到并行想考这一范式,咱们服气这一范式日后会爆发出广阔后劲。
作家简介
许浩然,浙江大学硕士。盘问标的为 Multi-Agent、Multi-Modal、RL等。以第一/共一作家身份在 ICML、ACL、CVPR、AAAI、ICLR等海外顶级会议发表多篇论文。通信单元为小米MiLMPlus团队。通信作家为李佳泽开云体育(kaiyun)官方网站,现任小米高等算法工程师,盘问标的为Multi-Agent, Agentic RL。